In the new image compression standard JPEG2000, the 9/7, 5/3 lifting wavelet transform is used as the encoding algorithm, and the 5/3 wavelet transform is a reversible integer transform, which can achieve lossless or lossy image compression. The algorithm is implemented on a general-purpose DSP chip with good scalability, scalability and easy maintenance. In this way, it is flexible and can fully meet various processing needs. 3 Simulation Results Table 1 lists the number of missing bits generated by the CPU when reading L1D. Among them, the lack of horizontal direction is inevitable. Since the boundary extension is performed on the right and bottom of the data block, the number of missing in the horizontal direction is slightly higher than the conventional method; in the vertical direction, the algorithm completely avoids the occurrence of the missing. Pod E-cigarette Shenzhen Yingyuan Technology Co.,ltd , https://www.smartpuffvape.com
1 Lifting algorithm The lifting algorithm [1] is proposed by Sweldens et al. based on the Mallat algorithm, also known as the second generation wavelet transform. Compared with the Mallat algorithm, the lifting algorithm does not rely on the Fourier transform, which reduces the amount of calculation and complexity, and the operating efficiency is correspondingly improved. Due to the characteristics of integer transformation and low cost storage unit, the lifting algorithm is very suitable for implementation on fixed-point DSP.
The basic idea of ​​the wavelet lifting algorithm is to gradually construct a new wavelet with better properties through basic wavelets. The implementation steps are split, predict, and update.
First, a new x(n) is obtained by symmetrically extending the original signal.
Decomposition is to divide the data into two parts: even sequence x (2n) and odd sequence x (2n+1);
The prediction is to predict the odd sequence with the even sequence of the decomposition, and the prediction error is the transformed high frequency component: H(n)=x(2n+1)-{[x(2n)+x(2n+2)]>> 1}
The update is to update the even sequence from the prediction error to obtain the transformed low frequency component: L(n)=x(2n)+{[H(n)+H(n-1)+2]>>2}
The calculation process is shown in Figure 1. 
2 Optimization strategy based on DM642
2.1 DM642 two-level CACHE structure
The DM642 is a processor specifically designed for multimedia applications and is a good platform for building multimedia communication systems. It uses a C64xDSP core, and the on-chip RAM uses a two-level CACHE structure [4][5], which is divided into L1P, L1D, and L2. L1 can only be accessed by the CPU as CACHE, all 16KB, the access period is consistent with the CPU cycle, where L1P is direct mapping, L1D is two-way group correlation; L2 can be configured by program as CACHE and SRAM.
2.2 Improved algorithm structure The traditional wavelet transform transforms the entire image, transforming each row first, and then transforming each column. In this way, the algorithm is relatively inefficient when implemented on a DSP. Because the DSP's L1D is small, only 16KB, the entire image cannot be cached, so the raw image data is usually stored on a lower-speed external memory. In this way, the CPU will inevitably generate a miss every time a row of data is read from L1D. A large number of missing will seriously block the operation of the CPU and prolong the execution time of the program. In order to reduce the occurrence of the missing, the traditional transformation must be improved. The original transformation of the entire image is changed to the transformation of the block, that is, each time a block is taken out from the image, the row and column transformations are successively performed, and then stored in the coefficient buffer according to a certain rule, as shown in FIG. 2 . 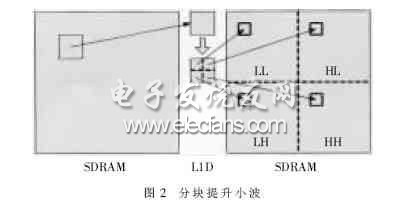
In this method, a data block in the SDRAM is first transferred to L2, then taken to L1D for horizontal lifting, and then the block is vertically raised. In this way, since the data required for vertical promotion is in L1D, the occurrence of data cache misses here is avoided, and the total number of missing numbers is greatly reduced.
2.3 Data transmission
(1) Data transfer between SDRAM and L2 Since EDMA[6][7] data transfer is independent of CPU operation, two caches are opened in L2: EDMA transfers the next block of data to InBuffB while the CPU processes InBuffA. Solved the delay caused by the CPU reading the low-speed device SDRAM, as shown in Figure 3. 
(2) Data transmission between L2 and L1D
The CPU first accesses the program and data in the first level CACHE. If there is no hit, it accesses the second level CACHE (if part of the L2 is configured as CACHE), if it is not hit, it needs to access the external storage space. During this process, the CPU is always blocked until the read data is valid. Therefore, when the data block in L2 is level raised, the CPU will generate a missing line for each line. In response to this situation, the TMS320C64x family of DSPs provides a streamlined processing mechanism for L1D for cache miss processing. If the number of misses is repeated multiple times, the CPU wait time will overlap, which generally reduces the CPU blocking time caused by the average miss.
Therefore, before the CPU raises the level of the data, the current data block is completely read into the L1D by using the missing pipeline technology, and then the data block is horizontally raised, and no missing occurs, and the operation speed can be improved.
2.4 L1P and L1D performance optimization
L1D is a two-way group, 8KB each, with a total capacity of 16KB. The data processed by the CPU at one time should not exceed 8 KB, and all the original data is continuously stored in the same CACHE group; the intermediate process data of the program remains in another CACHE group pre-allocated.
After the data is read into L1D, it is first expanded from 8 bits to 16 bits, and then the data is level raised. As long as the data can be retained in L1D, the subsequent vertical lifting can completely avoid the missing. Therefore, the size of the data block is determined by the intermediate process data. All intermediate process data cannot add up to more than 8 KB, and the selected data block is 32 & TImes;
When multiple functions are mapped to the same CACHE line of L1P, conflicts are missing, so these functions must be placed reasonably. Since all the functions that implement the promotion add up to no more than 16KB, if these functions can be arranged in a contiguous storage space, the L1P miss caused by the conflict can be completely avoided. You can add a GROUP to the SECTIONS of the cmd[8] file, and then put the frequently called functions into the GROUP:
SECTIONS
{
GROUP > ISRAM
{
.text:_horz
.text:_vert
.text:_IMG_pix_pand
...
}...}
2.5 Program Optimization From the previous analysis, it is known that when the image is subjected to lifting wavelet transform, it is necessary to extend its four boundaries. The continuation method adopts the symmetric extension shown in Figure 1, in which the left side and the upper side need to extend a point. When performing a lifting transformation on a block in an image, the extension of the block should be the boundary data of the four block data adjacent to the block, as shown in FIG. 
The boundary extension is mainly used to calculate the high frequency coefficient. The analysis found that when the level is raised, the last high frequency coefficient of each line of the current data block is the same as the first high frequency coefficient of the next block in the line. So as long as these coefficients of the current block are saved, the first high-frequency coefficient does not need to be calculated when the next block is horizontally upgraded, so there is no need to extend the left boundary. The same is true for vertical elevation. Add two arrays in the program to store the last high frequency coefficient of each row and column of the current block. By using this method, the complexity of the program can be reduced, the execution efficiency can be improved, and the occurrence of the missing can be reduced.
The pixel extension function pix_pand[9] is based on TI's IMGLIB algorithm library. The horizontal lifting and vertical lifting functions are written by the author in linear assembly language, making full use of the half-word processing instructions of the 64x series DSP, and using the half-word packaging technology to maximize the execution efficiency of the program.
When the level is raised, the data of each line is reordered to become the structure shown in FIG. 
Using the half-word processing instructions such as ADD2, SHR2, and SUB2 of C64x, the following two operations are executed in parallel:
H(1)=B-[(A+C)>>1]
H(2)=D-[(C+E)>>1]
When lifting vertically, you can arrange parallel execution of multiple columns of calculations, as shown in Figure 6.
H1(1)=B1-[(A1+C1)>>1]
H2(1)=B2-[(A2+C2)>>1] 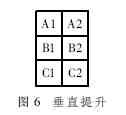
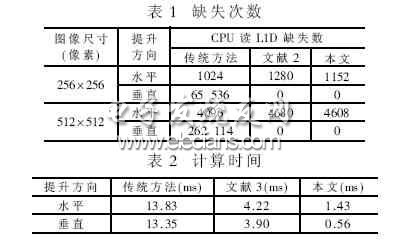
Table 2 lists the computational performance of several methods. Because this paper uses a variety of optimization techniques, the speed of operation is increased by 4 to 10 times. Tests have proven that these methods are very effective.